









Abstract
Recently, diffusion-based generative models have achieved remarkable success for image generation and edition. However, their use for video editing still faces important limitations. This paper introduces VidEdit, a novel method for zero-shot text-based video editing ensuring strong temporal and spatial consistency. Firstly, we propose to combine atlas-based and pre-trained text-to-image diffusion models to provide a training-free and efficient editing method, which by design fulfills temporal smoothness. Secondly, we leverage off-the-shelf panoptic segmenters along with edge detectors and adapt their use for conditioned diffusion-based atlas editing. This ensures a fine spatial control on targeted regions while strictly preserving the structure of the original video. Quantitative and qualitative experiments show that VidEdit outperforms state-of-the-art methods on DAVIS dataset, regarding semantic faithfulness, image preservation, and temporal consistency metrics. With this framework, processing a single video only takes approximately one minute, and it can generate multiple compatible edits based on a unique text prompt.
Method
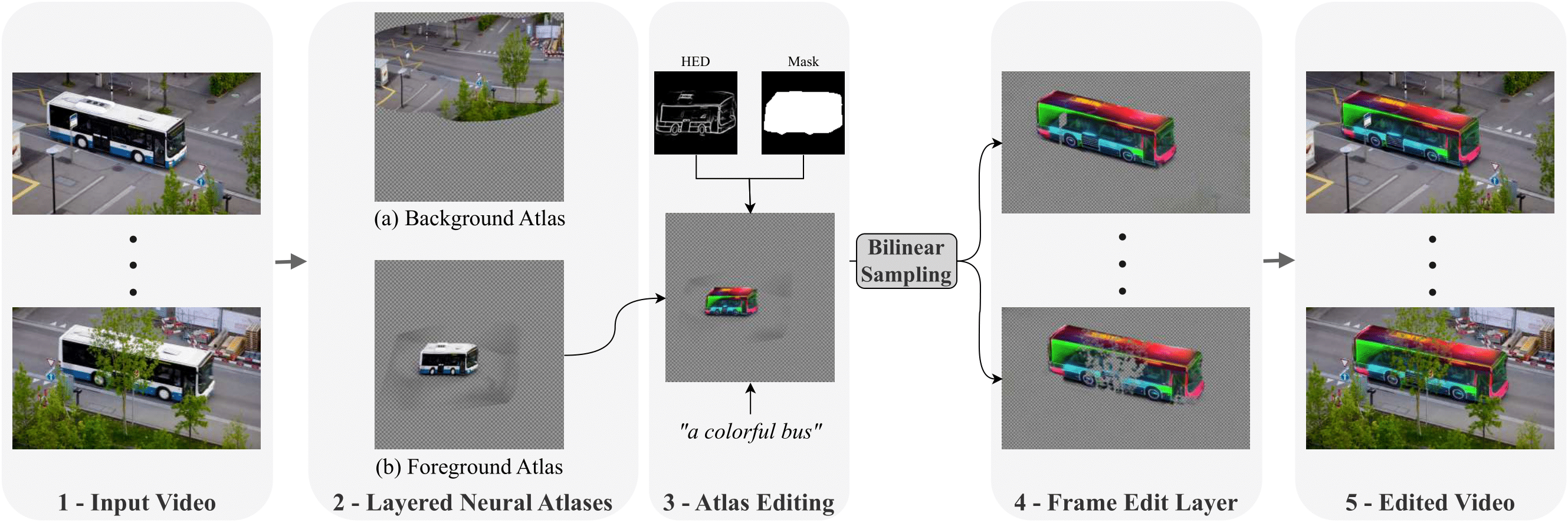
An input video (1) is fed into NLA models which learn to decompose it into 2D atlases (2). Depending on the object of interest, we select the corresponding atlas representation onto which we apply our editing diffusion pipeline (3). The edited atlas is then mapped back to frames via a bilinear sampling from the associated pre-trained network (4). Finally, the frame edit layers are composited over the original frames to obtain the desired edited video (5).
Bibtex